Frequently Asked Questions
Who is behind CSIndexbr?
CSIndexbr is maintained by the Applied Software Engineering Research Group, from Federal University of Minas Gerais, Brazil. However, our results are not endorsed by UFMG.
We also cannot assure the absence of errors, inconsitencies, and missing entries in the data provided by CSIndexbr. For this reason, the use of our data is at your own risk.
How to cite CSIndexbr?
Please cite this paper: CSIndexbr: Exploring the Brazilian Scientific Production in Computer Science. Marco Tulio Valente, Klerisson Paixao. arXiv abs/1807.09266, 2018. [pdf] [Bibtex]
How CSIndexbr works?
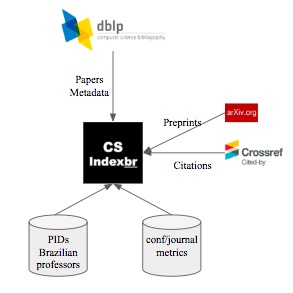
Papers are collected from DBLP. We also collect preprints from arXiv (see figure).
What is the license used by CSIndexbr?
Our code is available under a MIT license and our data is available under a CC BY-NC-SA 4.0 license. The latter grants free and non-commercial usage of our data, including adaptations. However, proper credit should be granted, by linking to CSIndexbr site and/or citing this paper. We also recommend to mention DBLP, since it is the primary source of the data collected by CSIndexbr.
What is your definition of a full paper?
It is a paper presented in the main track of a conference. We also apply a minimum page size threshold, such as:
- Software Engineering, Programming Languages, Information Systems, Databases, Web & Information Retrieval: 10 pages
- Computer Networks, Distributed Systems, Human-Computer Interaction: 8 pages
Do you have plans to cover short papers (including demos, tool papers, early research papers, industry track papers etc)?
No, in the case of conferences, we only collect full papers, describing mature and carefully evaluated work. These papers should be viewed as journal-quality papers.
Why my paper is not listed?
In the case of conferences, check if it is a full paper, published in the main track of the event, in the last five years. If this the case, please use this form and provide data about your paper.
Which conferences are tracked?
We do not intend to cover all CS conferences. Our interest is on journal-quality conferences, with good metrics and well-known sponsors (ACM SIGs, IEEE CS, etc). Particularly, conferences should attend the following thresholds:
- submitted > 100 papers
- acceptance < 30%
- h5-index > 20
We also do not track multi-conferences, since it is not possible to retrieve the h5-index of each of their conferences or tracks.
Furthermore, we set up a limit of 15 conferences per research area (the exception is Computer Networks, with 18 conferences).
Which journals are tracked?
First, journals must be indexed by Journal Citation Reports (JCR). Second, we look for journals attending the following thresholds:
- h5-index > 25
- Why having a limit of 15 journals per area? Because our goal is to index only the most important venues (journals or conferences) of each area. To access the full list of publications of a researcher, please check his/her DBLP page.
- Why JCR's impact factor is not used? Because JCR has a restrict license; for example "sharing of JCR data outside a subscriber’s institution is strictly prohibited".
Why conference [Conf] or [Journal] are not covered?
We accept suggestions to track other conferences or journals. However, please check if they attend the thresholds defined in the previous questions. If you think this is the case, please use this form to inform the metrics about [Conf] or [Journal].
How do you define top-conferences?
First, top-conferences should have:
- submitted > 180 papers and
- h5-index > 30.
- Why some areas have more than 3 top-conferences or journals? Because they are a combination or include distint areas. For example, we have five top-conferences in Computer Networks, but it includes Mobile Computing, which has even a dedicated ACM SIG.
- Why not divide an area with more than 3 top-conferences in areas X and Y? Because there are journals that publish papers both in X and Y.
How do you define top-journals?
We define as top-journals the Transactions published by ACM and IEEE Computer Society (or IEEE Computational Intelligence Society, in the case of AI journals; or IEEE Robotics and Automation Society, in the case of Robotics journals; or INFORMS, in the case of Operational Research).
Moreover, there is a limit of 3 top-journals per resarch area.
What is the meaning of "other" in the journals Rank column (Stats tab)?
These journals are scored as conferences (weight 0.33, instead of 0.40). The following journals are classified in this category:
- Magazines and journals that accept short papers (which must have at least 6 pages)
- Journals that accept more than 500 papers/year
- Journals with normalized-h5-index < 0.2
How is the departments' score computed?
Using this formula:
- score = A + (0.4 * B) + (0.33 * C)
- A = number of papers in top-venues (journals or conferences)
- B = number of papers in journals
- C = number of papers in conferences, magazines, journals that accept short papers, or in "other" journals